Development
Goal
The sgs online version is planned to include the transcribed and annotated spontaneous speech recordings (anonymized in accordance with ethical norms in social research), the results of a gradient acceptability judgment task and parts of the social metadata along with the possibility to query the data across languages and data types.
For instance, the online resource would make it possible to search for syntactic, semantic and information-structural features of left-dislocated elements in French and Spanish contrastively. Or, to give another example, we could ask if speakers with different social backgrounds differ in their preference for wh-in-situ questions vs. questions involving wh-movement, both in the acceptability rating task and in spontaneous speech.
Current state
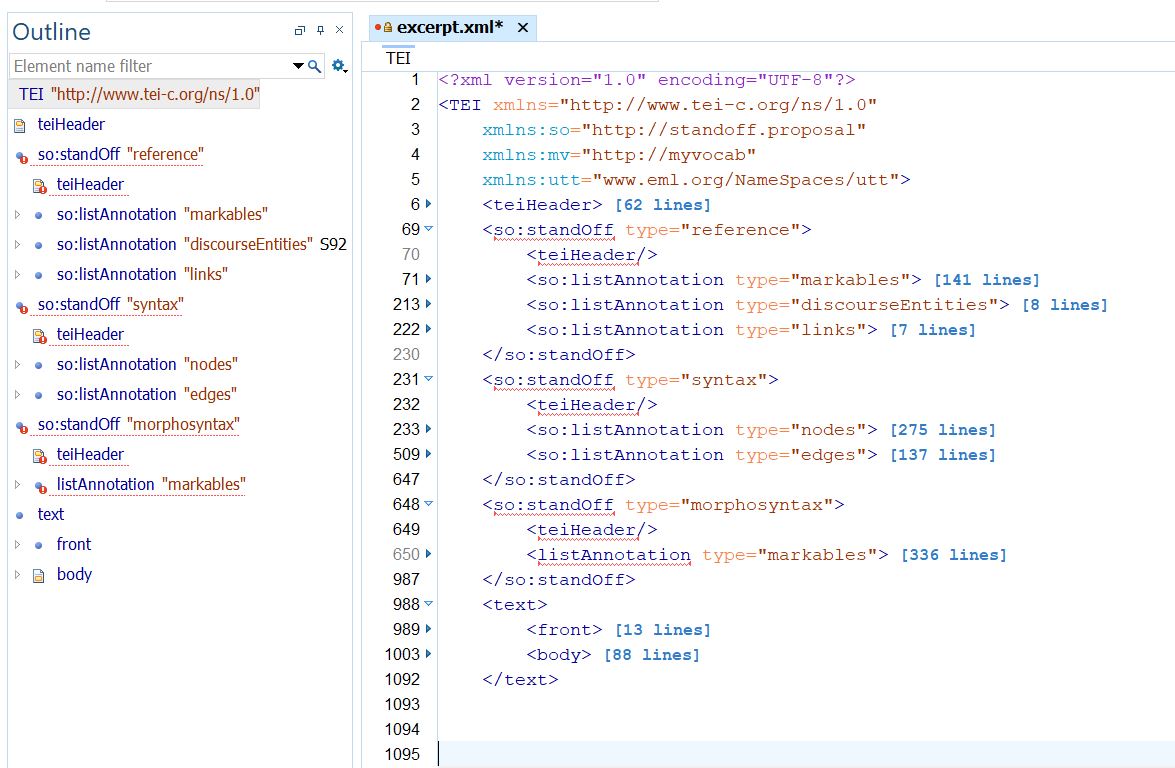
In the first version of the annotation, linguistic information was added to the transcription in the sgsTree format, a system of in-line tags following each matrix clause that was specifically developed for this project. The processing was carried out through a Perl script which took the idiosyncratic annotation format as input and exported the search result to plain text or to SPSS for further statistical analysis.
As a first step towards an online accessible, more user-friendly version of the corpus, we began converting the existing annotation to the XML-TEI format with the help of Dr. Laurent Romary (INRIA). The TEI format proves useful as a unified data representation format and in terms of its inter-operability with existing corpus annotation and processing software (EXMARaLDA, MMAX2, ANNIS, etc.). In the next step, the morpho-syntactic layer has been added. Currently, we are in the process of adding the syntactic information and the reference analysis.